| 2.cdh 大数据平台搭建 | 您所在的位置:网站首页 › mysql hugepage › 2.cdh 大数据平台搭建 |
2.cdh 大数据平台搭建
|
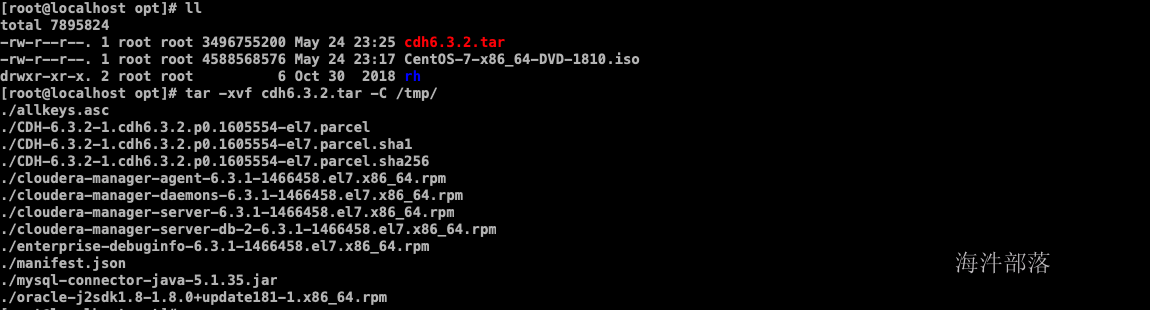
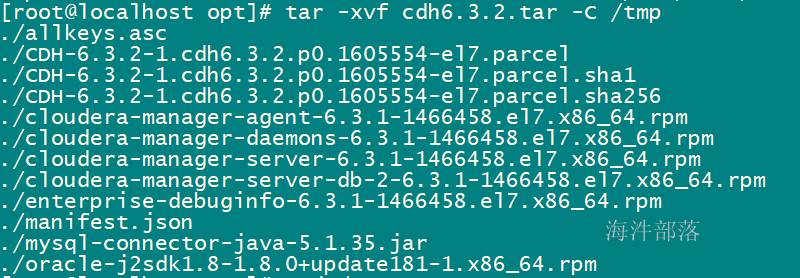
1 安装包下载 安装介质外网下载地址如下: 链接: https://pan.baidu.com/s/1dyvSej5tSrUC4ja8-usqvA 提取码: a9hx 2 cdh集群安装 2.1 上传压缩包 上传cdh6.3.2.tar安装包到linux服务器,并解压 tar -xvf cdh6.3.2.tar -C /tmp/
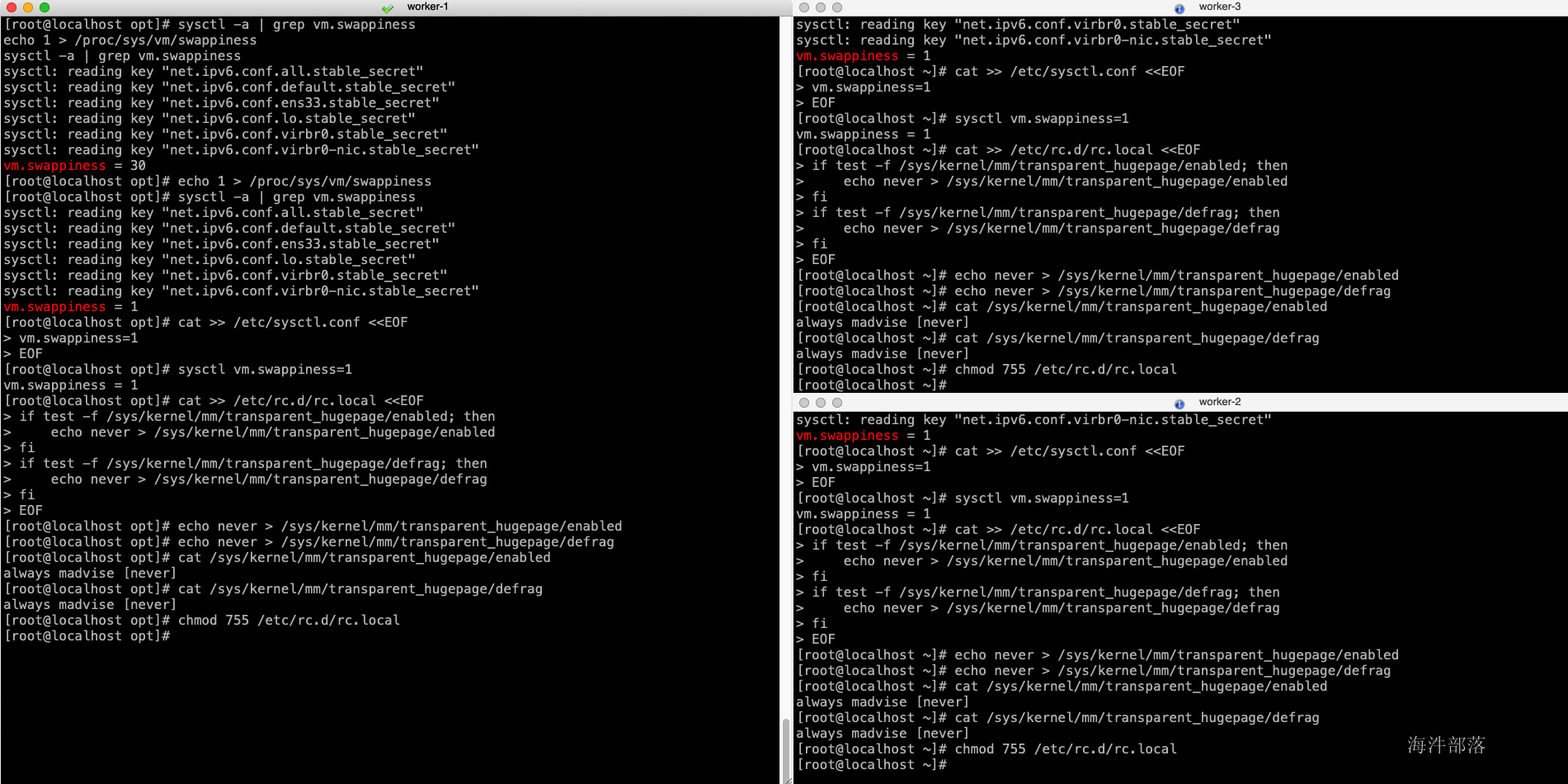
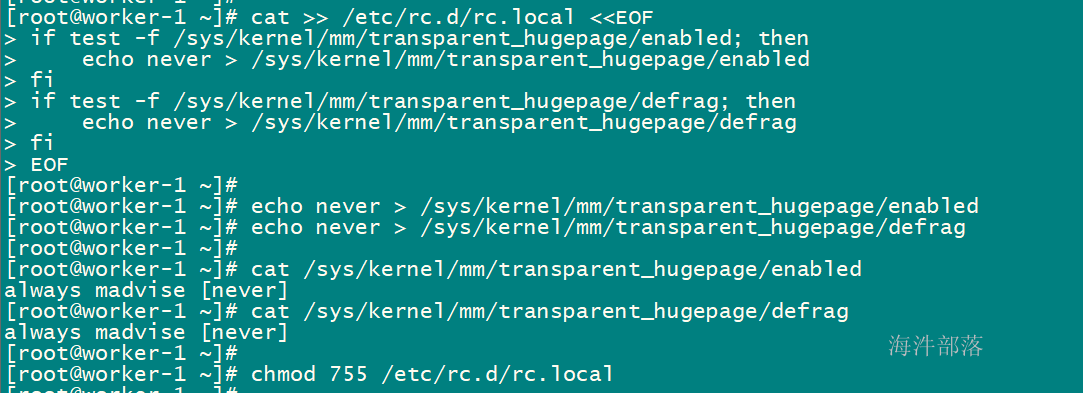
expect安装 配置目的:安装 expect 命令,实现脚本交互 # 在所有节点上安装 yum install expect -ypstree安装 配置目的:rhel 7 默认没有pstree命令,使用以下命令进行安装,cdh基础依赖。 # 在所有节点上安装 yum install psmisc -yperl 安装 配置目的:解决最小安装时,客户端部署报错,在最小化安装的时候是没有安装perl的。 #所有节点 yum install perl -yhttpd服务安装 配置目的:本地源配置使用 #所有节点 yum install httpd mod_ssl -ykudu 需要以下组件 配置目的:kudu依赖 #所有节点 yum install gcc python-devel -y yum install cyrus-sasl* -y 2.3 调整host文件 配置目的:域名访问 # 在所有节点执行,替换为自己环境实际ip与hostname cat >> /etc/hosts > /etc/sysctl.conf /etc/rc.d/rc.local /sys/kernel/mm/transparent_hugepage/defrag fi EOF #配置即刻生效 echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag #检查配置是否生效 cat /sys/kernel/mm/transparent_hugepage/enabled cat /sys/kernel/mm/transparent_hugepage/defrag #赋予执行权限 chmod 755 /etc/rc.d/rc.local
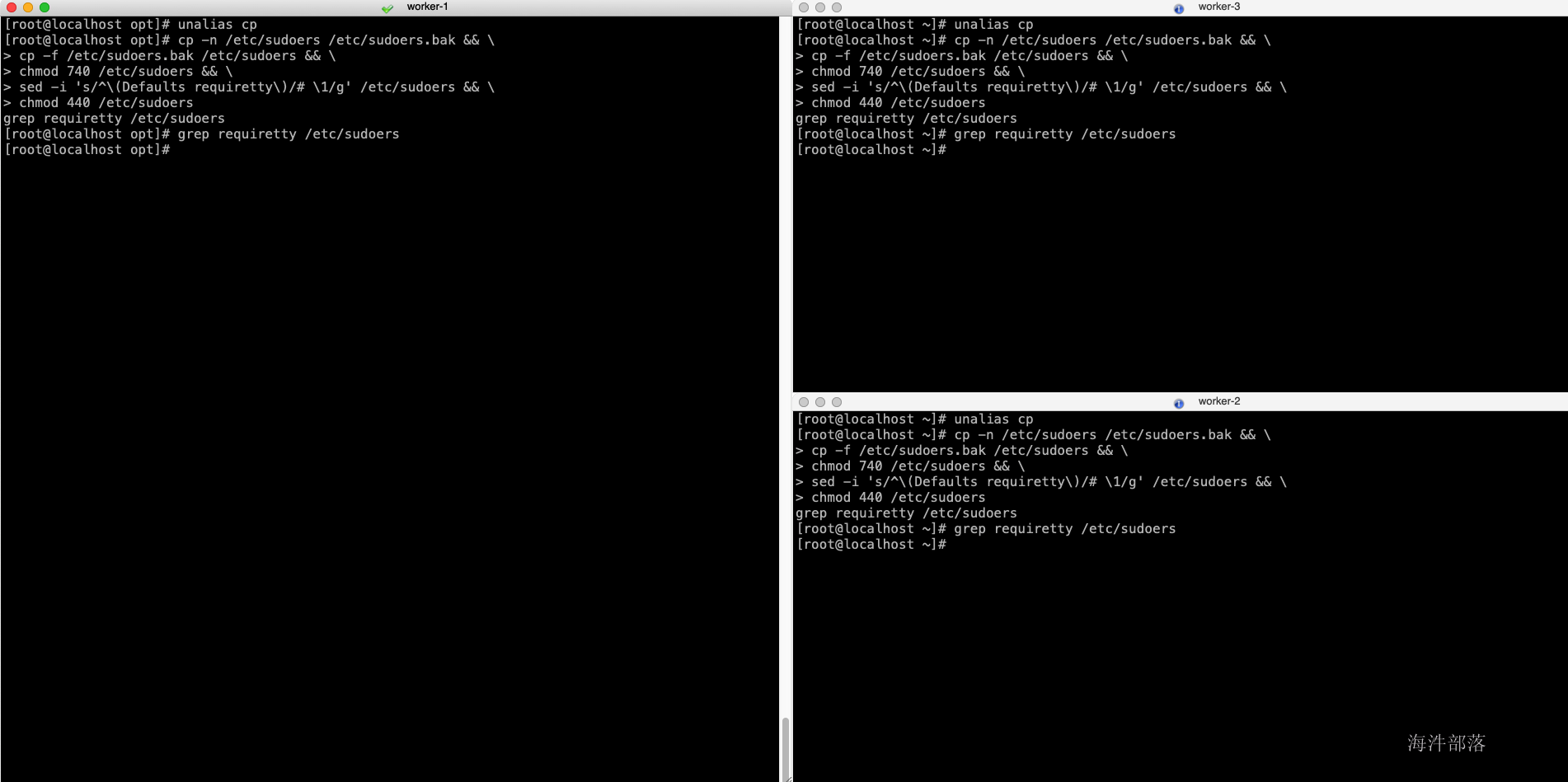
配置目的:sudo相关 #所有节点执行 unalias cp cp -n /etc/sudoers /etc/sudoers.bak && \ cp -f /etc/sudoers.bak /etc/sudoers && \ chmod 740 /etc/sudoers && \ sed -i 's/^\(Defaults requiretty\)/# \1/g' /etc/sudoers && \ chmod 440 /etc/sudoers grep requiretty /etc/sudoers
配置目的:在安全认证的时候需要保证每个节点的时间同步,如果不同步则offerset过大,进而影响安全认证,比如凭证生命周期过期,在后面kerberos的原理部门会讲到sessionkey,这个就是一个较短声明周期的key,如果节点间时间差距较大,则直接导致key失败。 # 所有节点执行,安装ntp服务 yum install ntp -y # 主节点执行,在主节点中设置本地地址,注意只能使用ip mv -n /etc/ntp.conf /etc/ntp.conf.bak cat > /etc/ntp.conf /etc/ntp.conf > /etc/profile ...这里的主机名称为你要配置的所有节点的hostname,需要在你本机的hosts中也配置了这些节点。
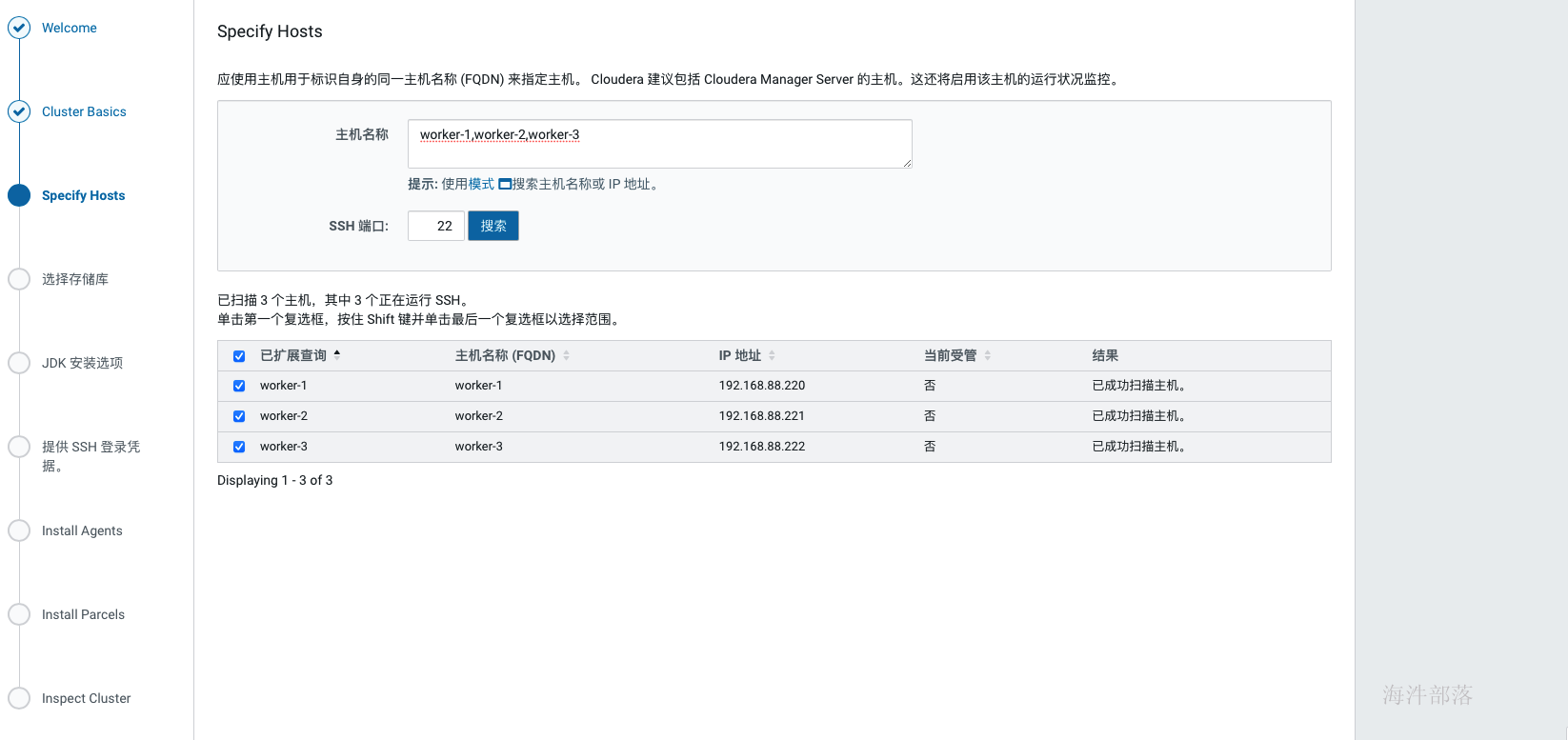
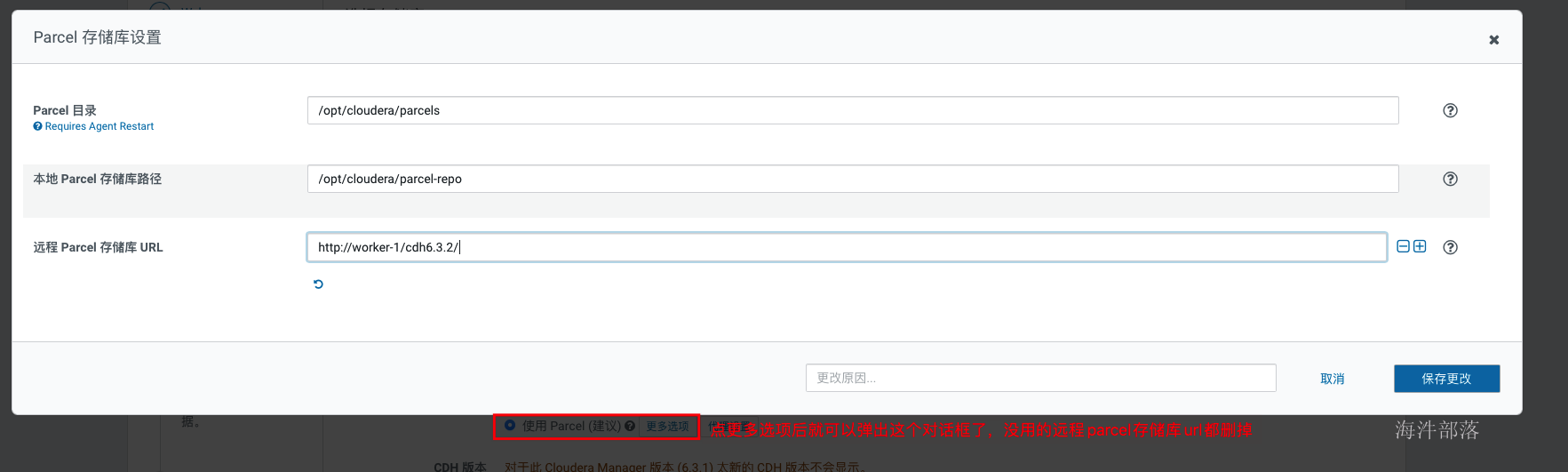
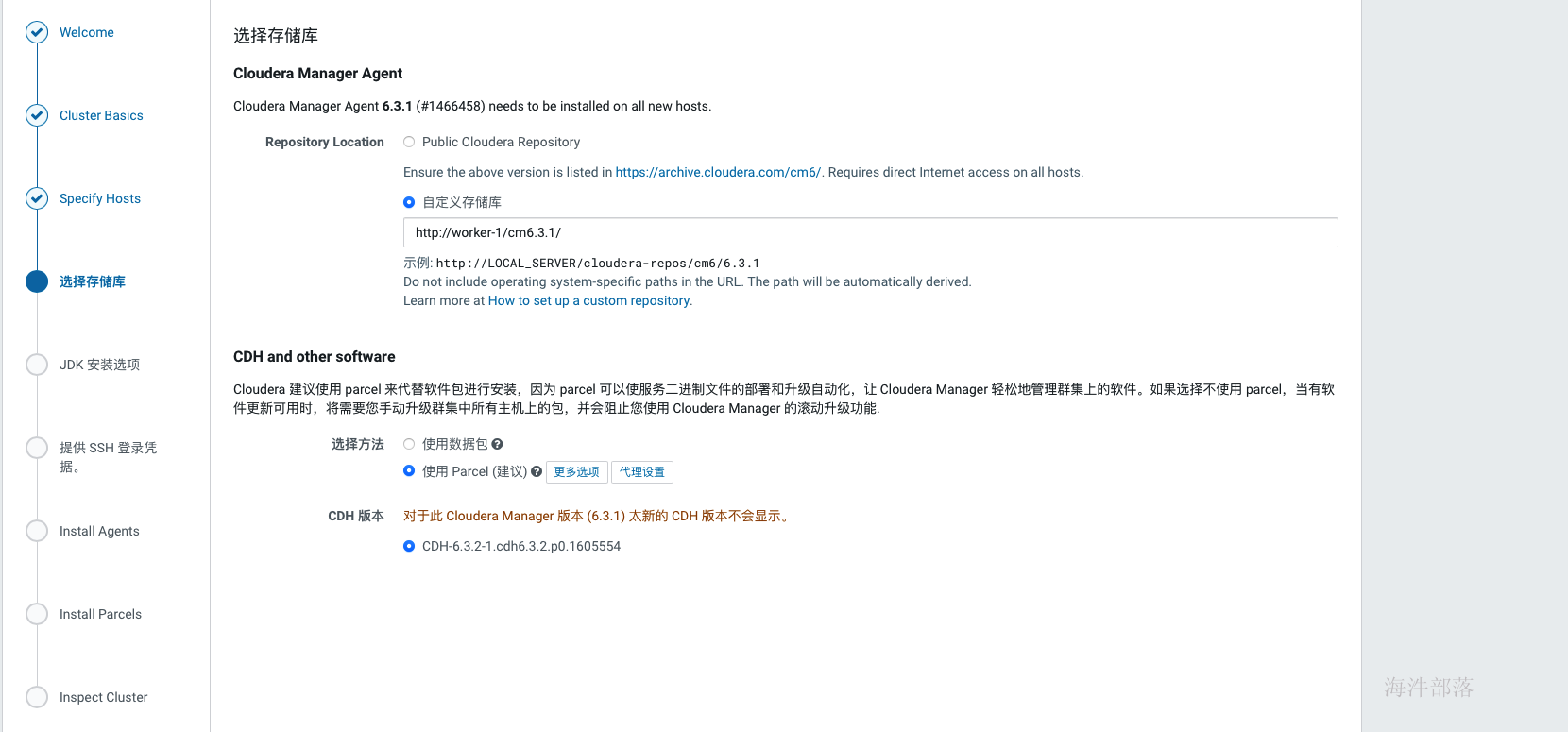
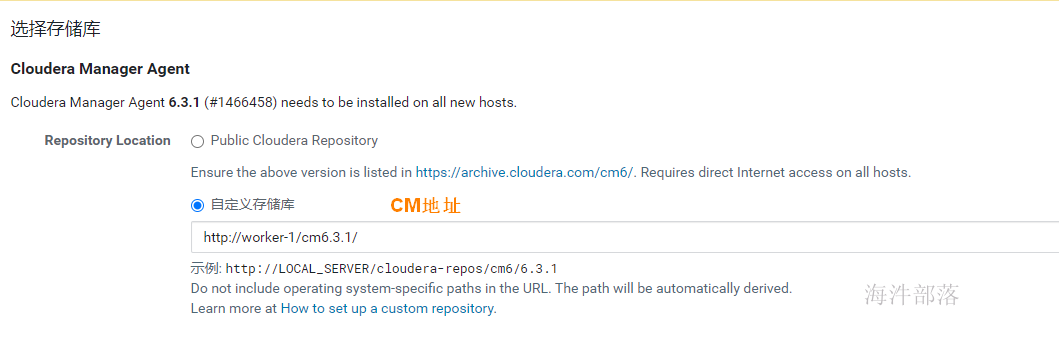
集群安装时库选择,这里使用的就是我们前面配置的httpd服务,使用本地下载,避免在线安装的各种问题。域名改成自己相应的域名。 parcel的远程安装库为:http://worker-1/cdh6.3.2/ agent的远程安装库为:http://worker-1/cm6.3.1/
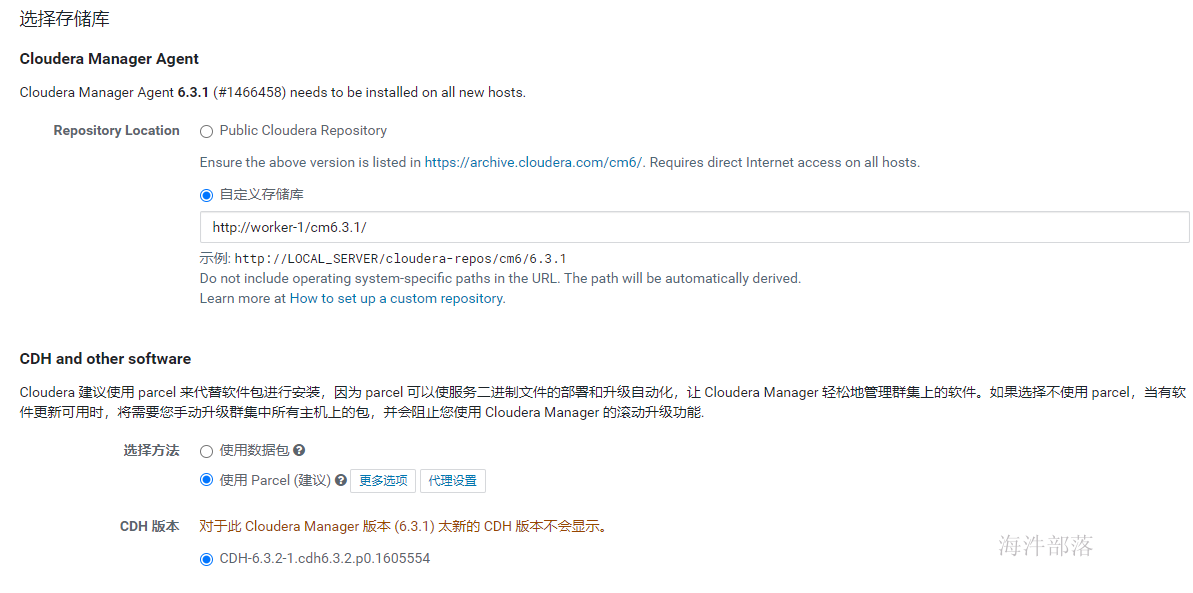
如上,当正确填写完parcel地址后,会自动识别出cdh版本,否则……,重新检查在配置httpd服务的时候是否已经执行createrepo. 接下来就会安装cdh的agent节点,如下
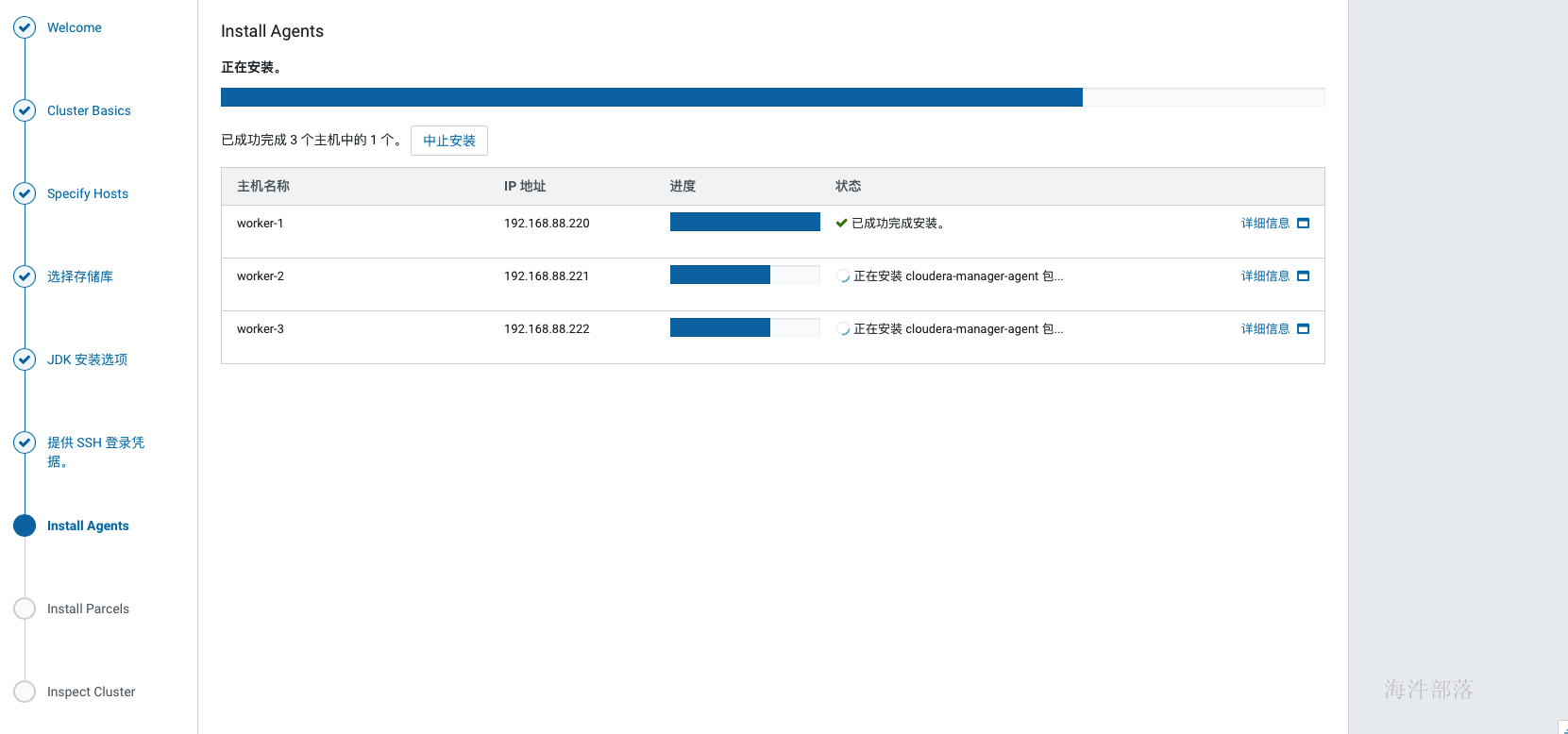
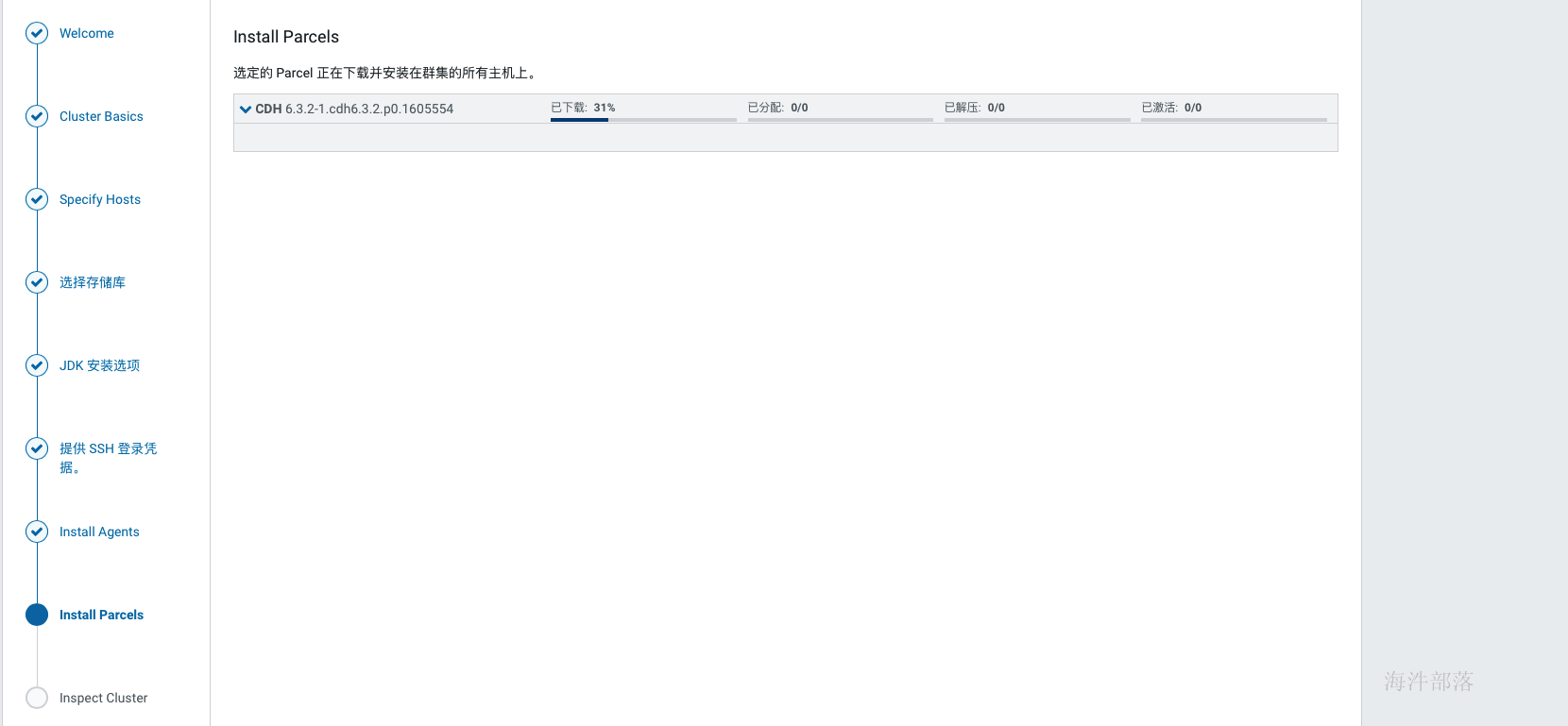
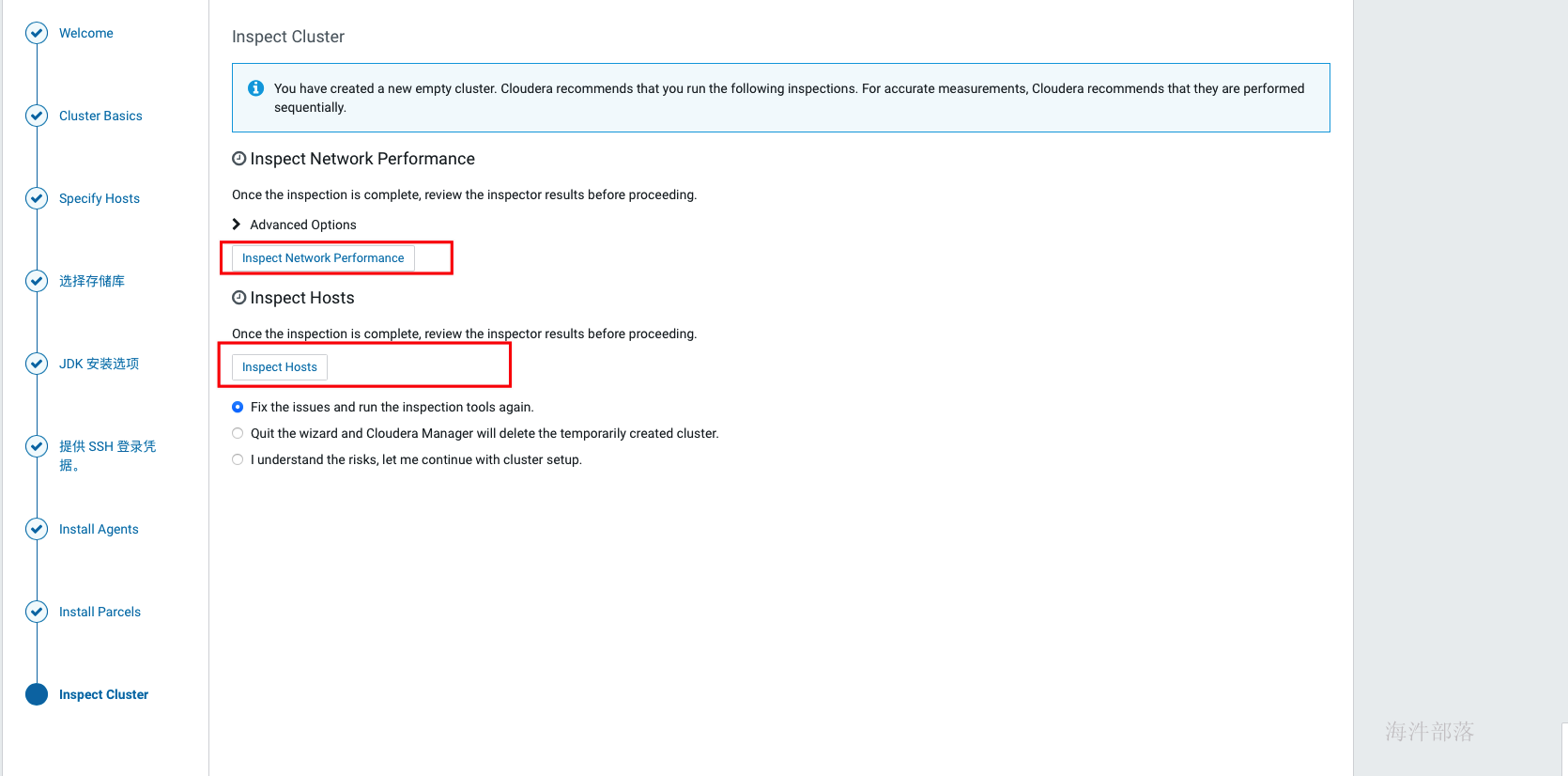
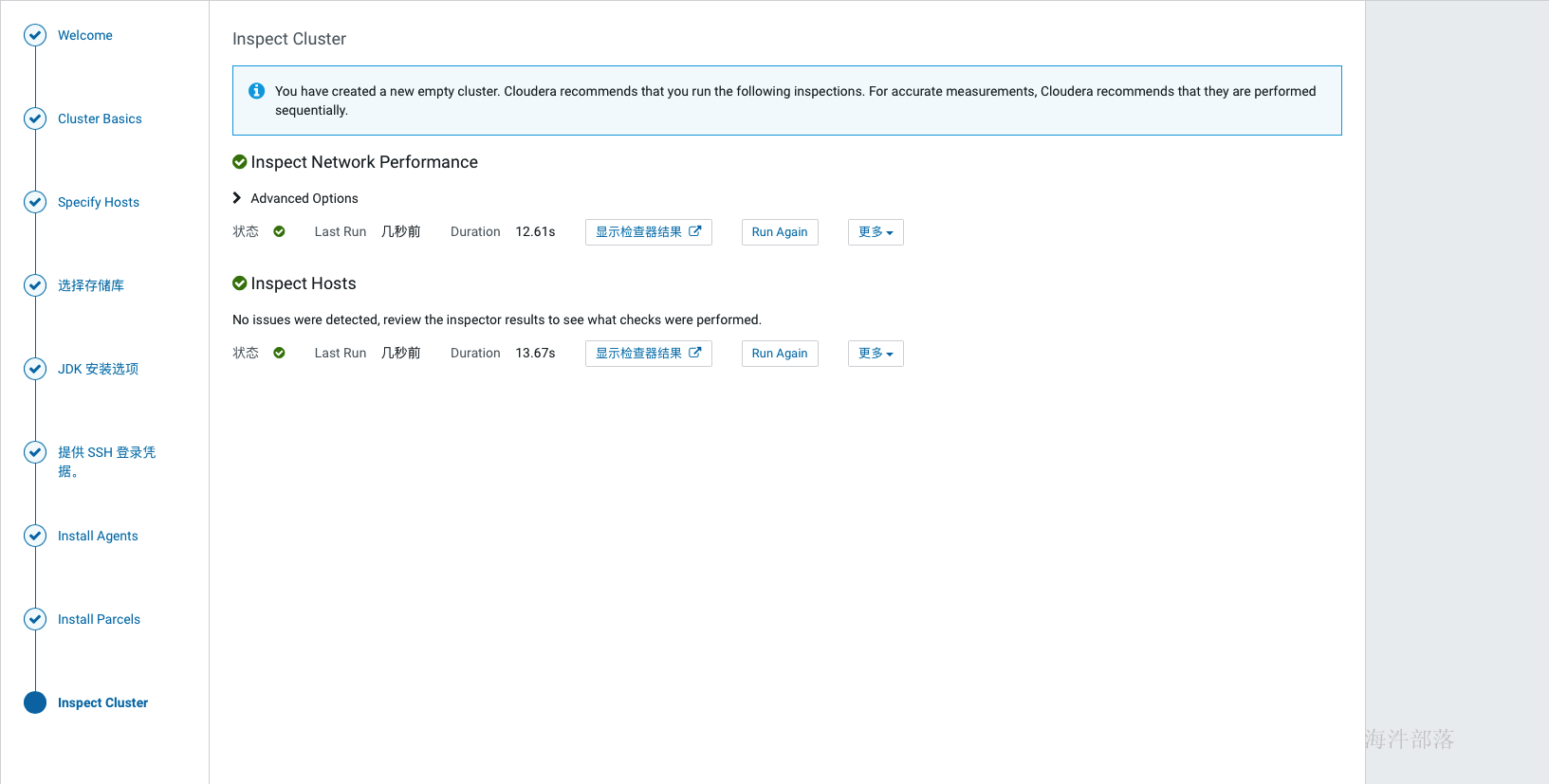
当agent安装完成后,会进入到安装parcels的界面,这里也是自动进行的,如果中间出现各种错误,可以查看日志定位,在web界面上就可以看到错误日志,也可以在cm的日志中查找,/var/log目录下Cloudera manager server的日志。常见的问题没有正确配置本地源会导致下载失败、分配失败可以优先检查互信配置与hosts配置,过了下载和分配后如果解压失败则优先检查磁盘空间,激活没遇到过失败的。
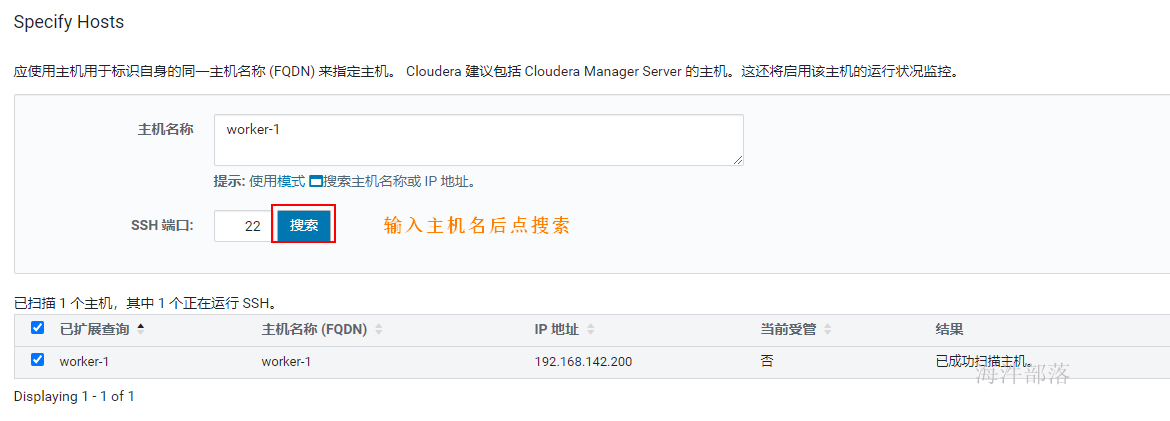
如上激活完成后,跳转到检查环境的缓解,点击如下标红位置分别检查网络与hosts,检查通过后才可以继续,如果是单节点安装,在hosts检查的时候会报错,此时选择i understand the risks,let me continue with cluster setup选项 然后点击继续。
如上,环境检查完成后,进行选择安装组件的环节,可以先选择一些基础组件安装,后面需要什么组件在添加即可。比如可以先安装hdfs、hive、hue、yarn、zookeeper,其他服务等集群全部安装完成后再集成,因为部分组件间有依赖关系,如果缺少了依赖,那会导致安装失败。
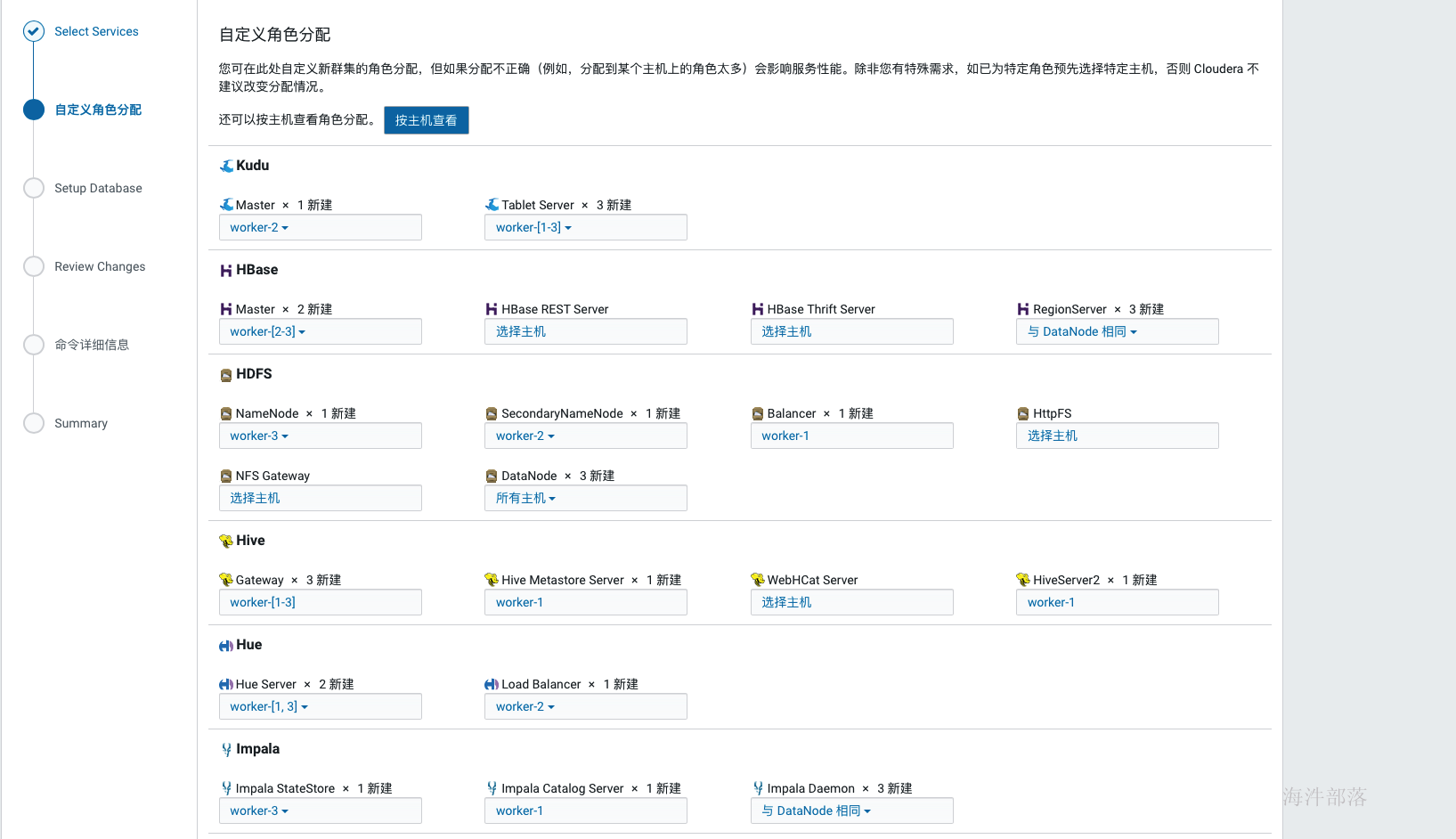
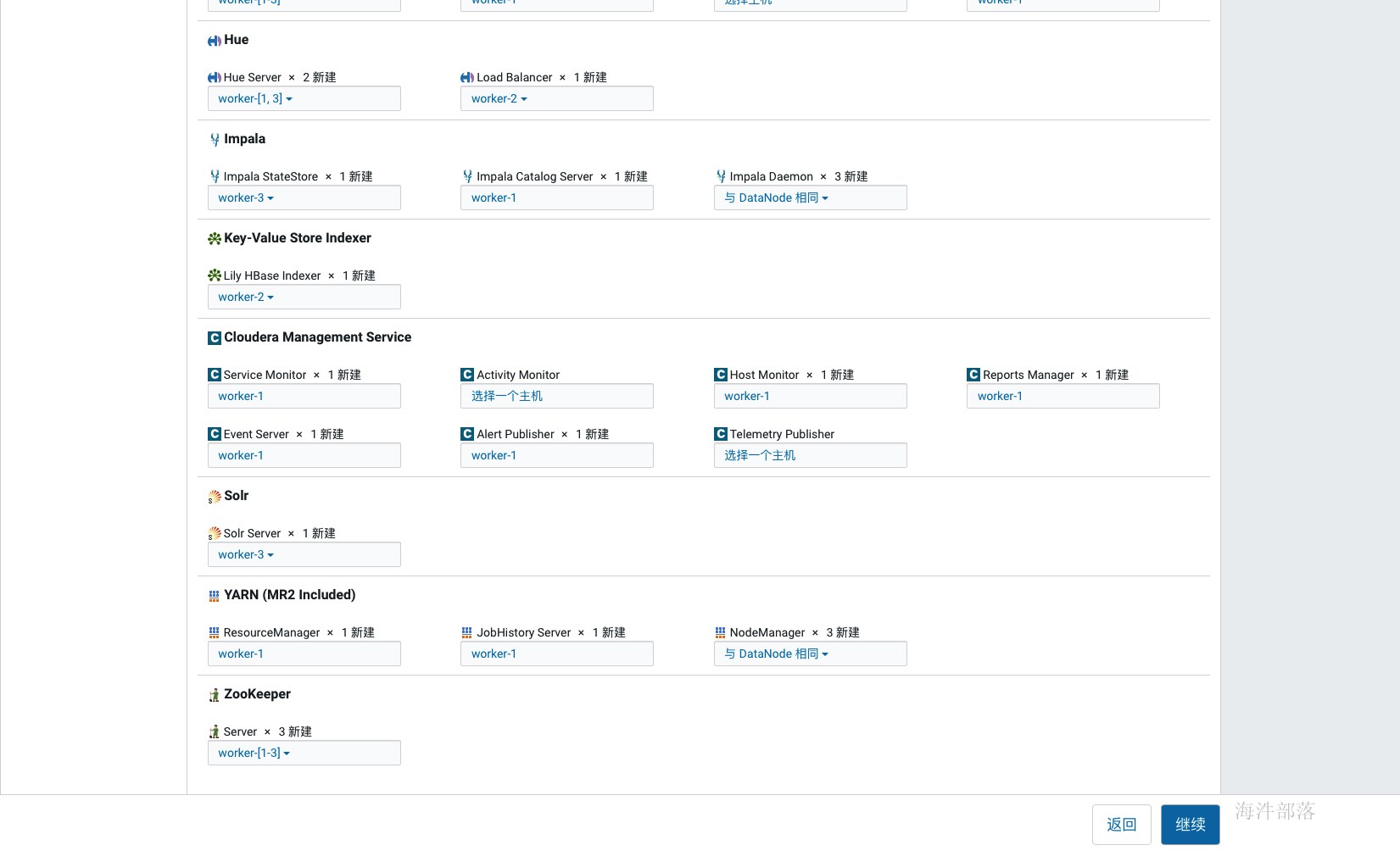
如上选择好安装组件后点击继续,为每个服务配置节点,如果是单节点就没得选择了,在生产环境中这个规划通常在角色规划中已经规划好,按照架构设计配置即可,通常我们会选择一个管理节点,这个管理节点上部署一些管理服务,其他计算与存储节点上不部署管理服务,如果节点资源紧张也可以在管理节点上部署存储与计算服务,还有一种极端的情况就是节点资源都很紧张,那面就要把服务尽量均衡到每个节点上,除个别服务,比如hive的元库肯定部署在和mysql相同的节点上。
如上完成节点配置后点击继续,进入到元库配置环节,这里配置的信息即我们在12. 创建cm元数据库时创建的那些库的信息,配置完成后点击test connection,只有测试通过后才可以继续。
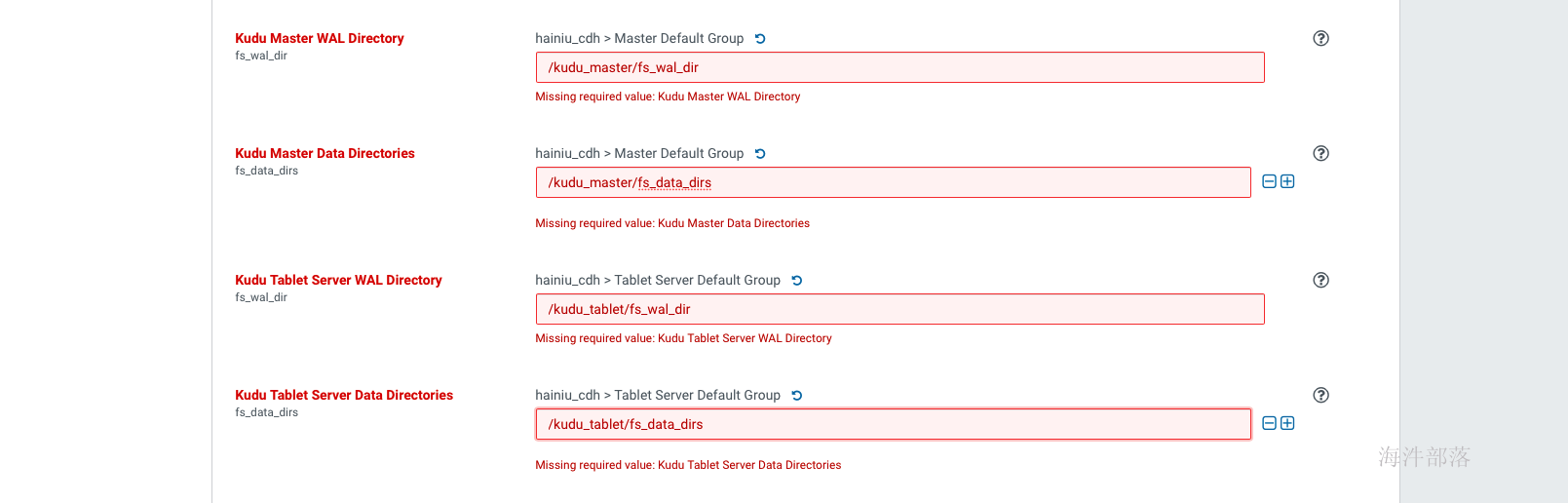
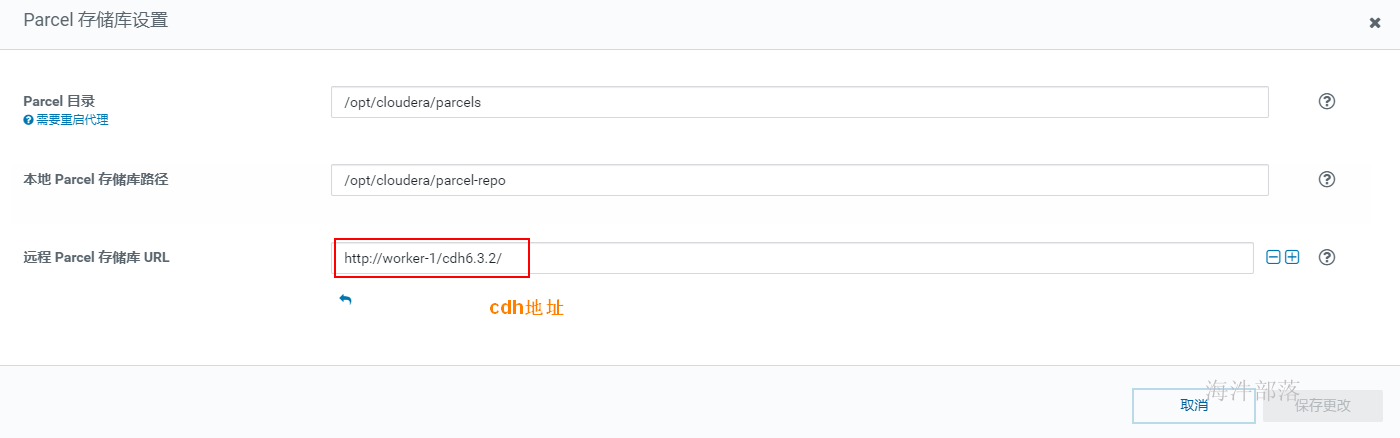
如上配置完元库信息并通过连接测试后,点击继续,进入服务详细配置界面,如果选择了安装kudu服务,则需要填写四个kudu的目录,如下, Kudu在安装时需要填写以下几项内容: Kudu Master WAL Directory: /kudu_master/fs_wal_dir Kudu Master Data Directories: /kudu_master/fs_data_dirs Kudu Tablet Server WAL Directory: /kudu_tablet/fs_wal_dir Kudu Tablet Server Data Directories: /kudu_tablet/fs_data_dirs 这四个目录,通常与hdfs的盘分离(官方也没有给出为什么,但是在生产中确实遇到过kudu与hdfs同盘导致服务不能启动的问题),我们在测试学习环境下可以设置在一起,如果要使用虚拟机分盘则需要再添加一块虚拟盘,挂载在指定目录下,专门给kudu使用。 生产环境下肯定是配置非常多的数据盘,在配置dfs目录的时候可以点击后面的+增加盘路径(如果所有盘都挂载到了一个目录下,那就不用增加了)
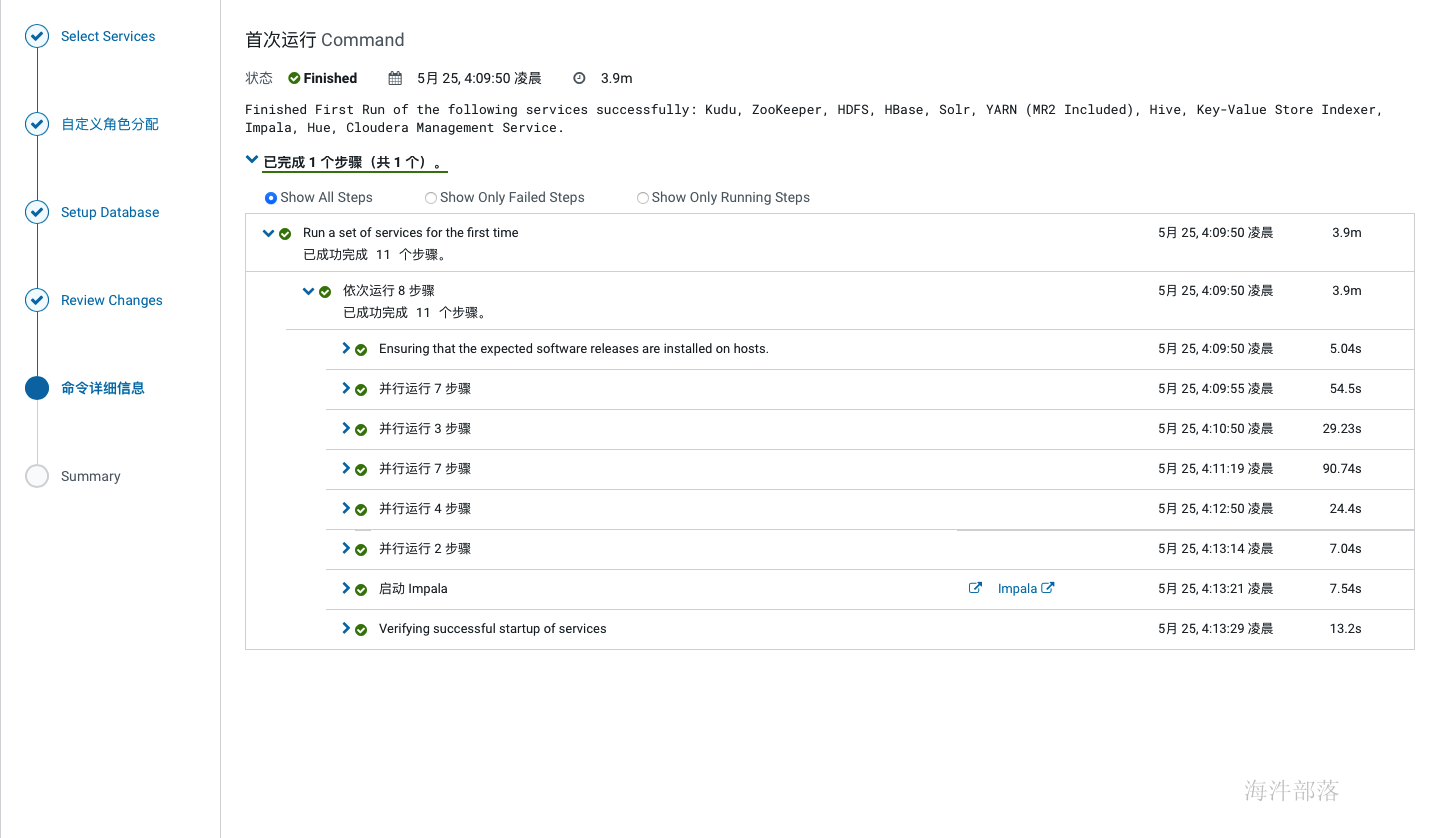
如上配置完成后点击继续,开始服务的安装,如下:
如上,服务全部安装完成后,会进入到cm界面,如下,此时集群安装就完成了。
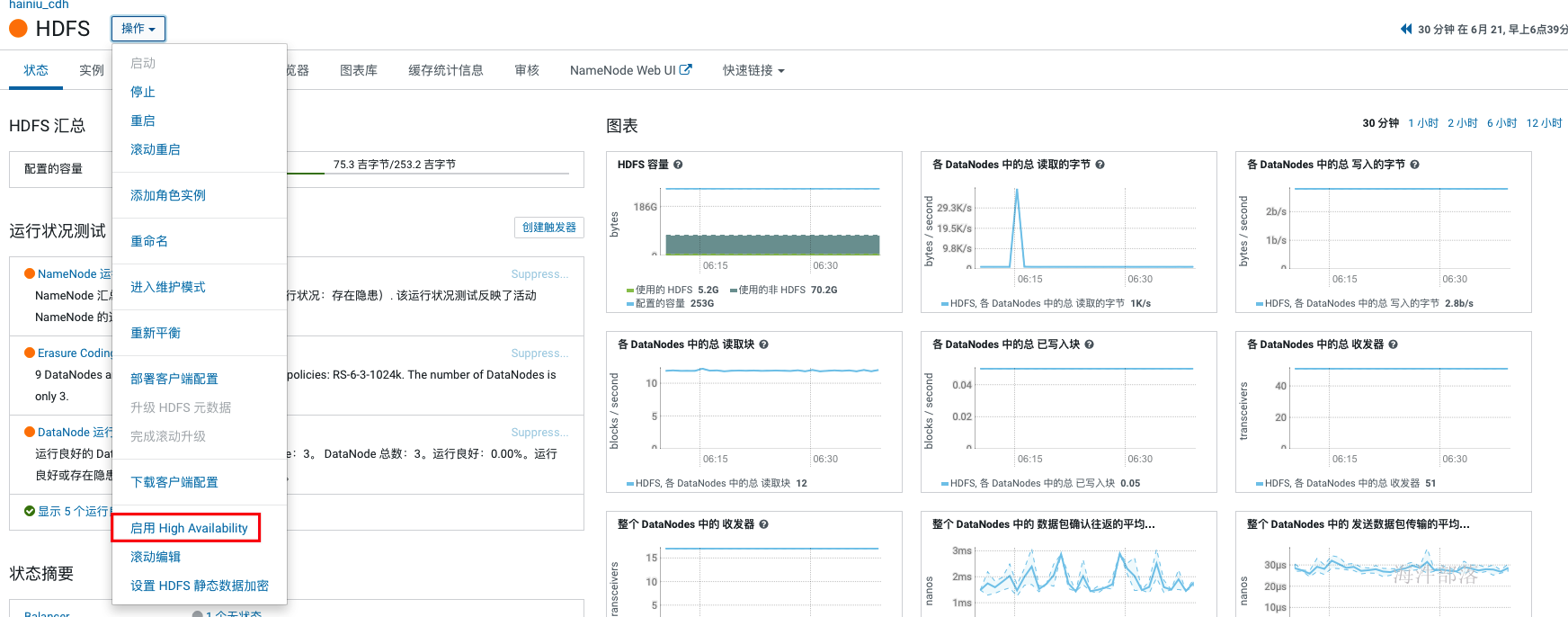
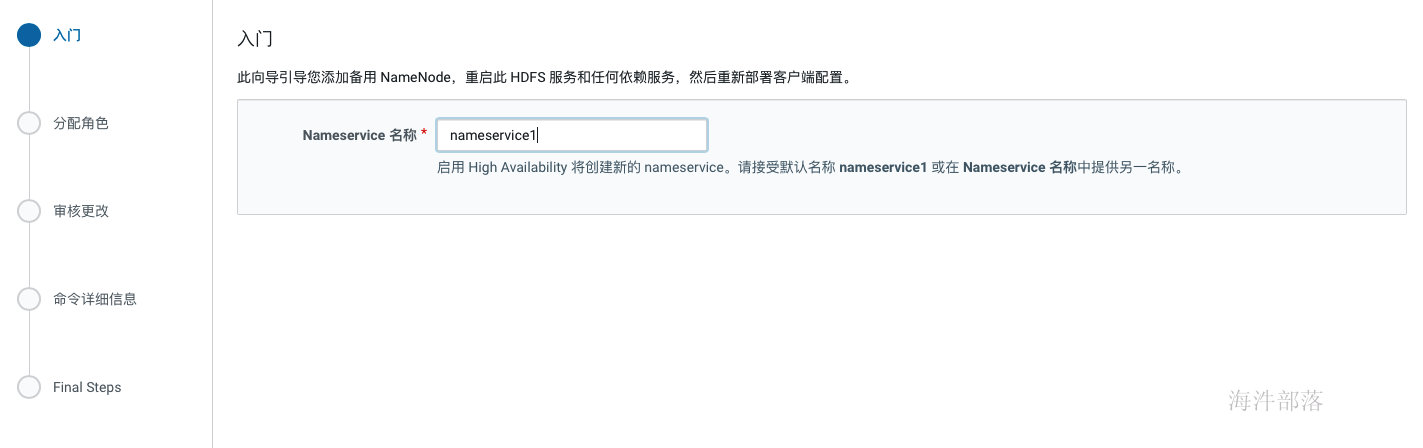
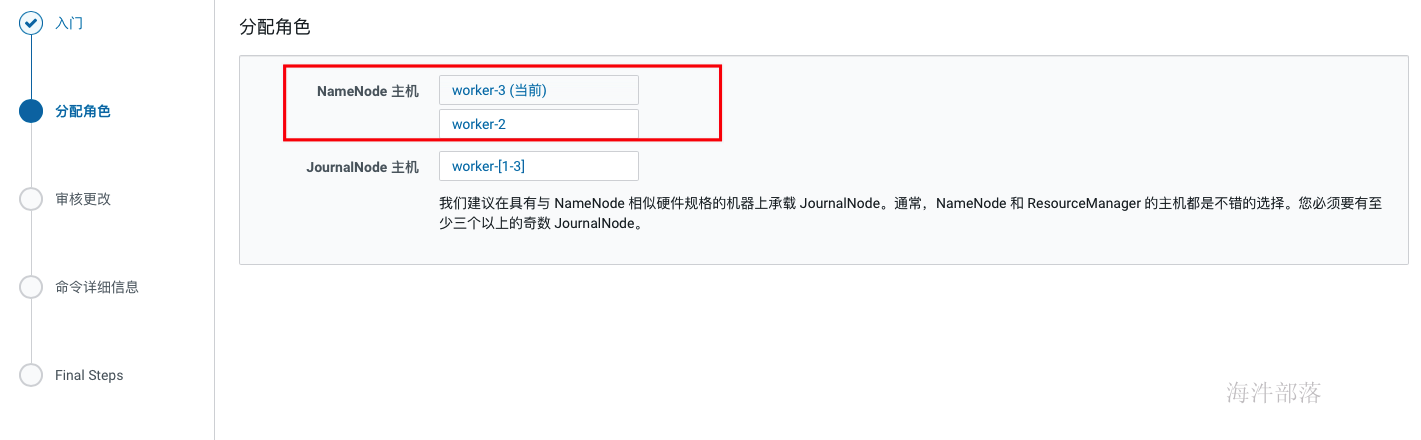
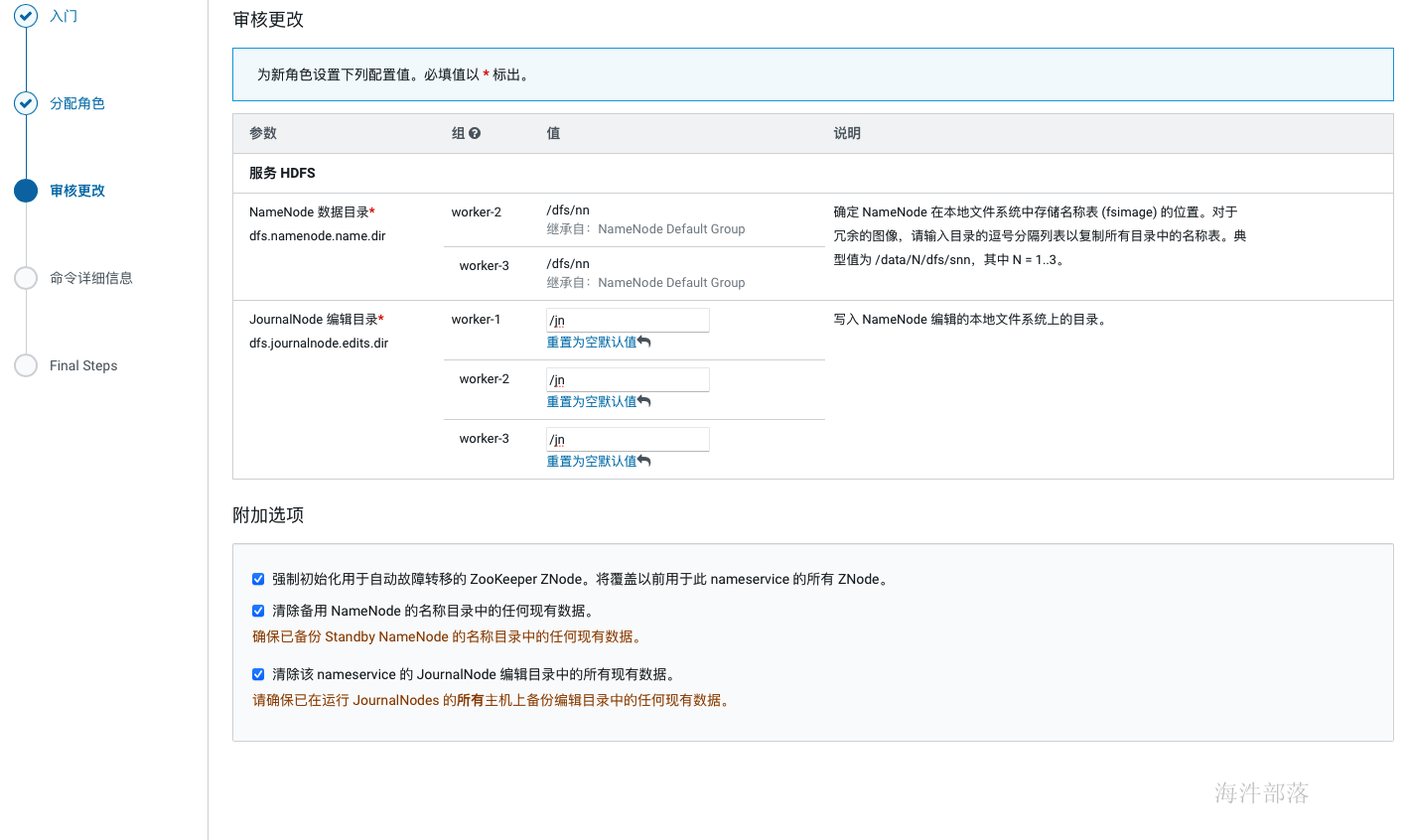
单点部署时HDFS 副本不足告警:Under-Replicated Blocks,这个警告的意思是在一个节点上部署分布式毫无意义,他们希望至少要有三个节点。 针对这种情况,我们就修改 dfs.replication 参数为1(在hdfs组件的配置中搜索replication),然后执行以下命令将所有文件副本数设置为1: sudo -u hdfs hadoop fs -setrep -R 1 / 2.17 开启HA hdfs组件操作下拉按钮中选择启用high availability
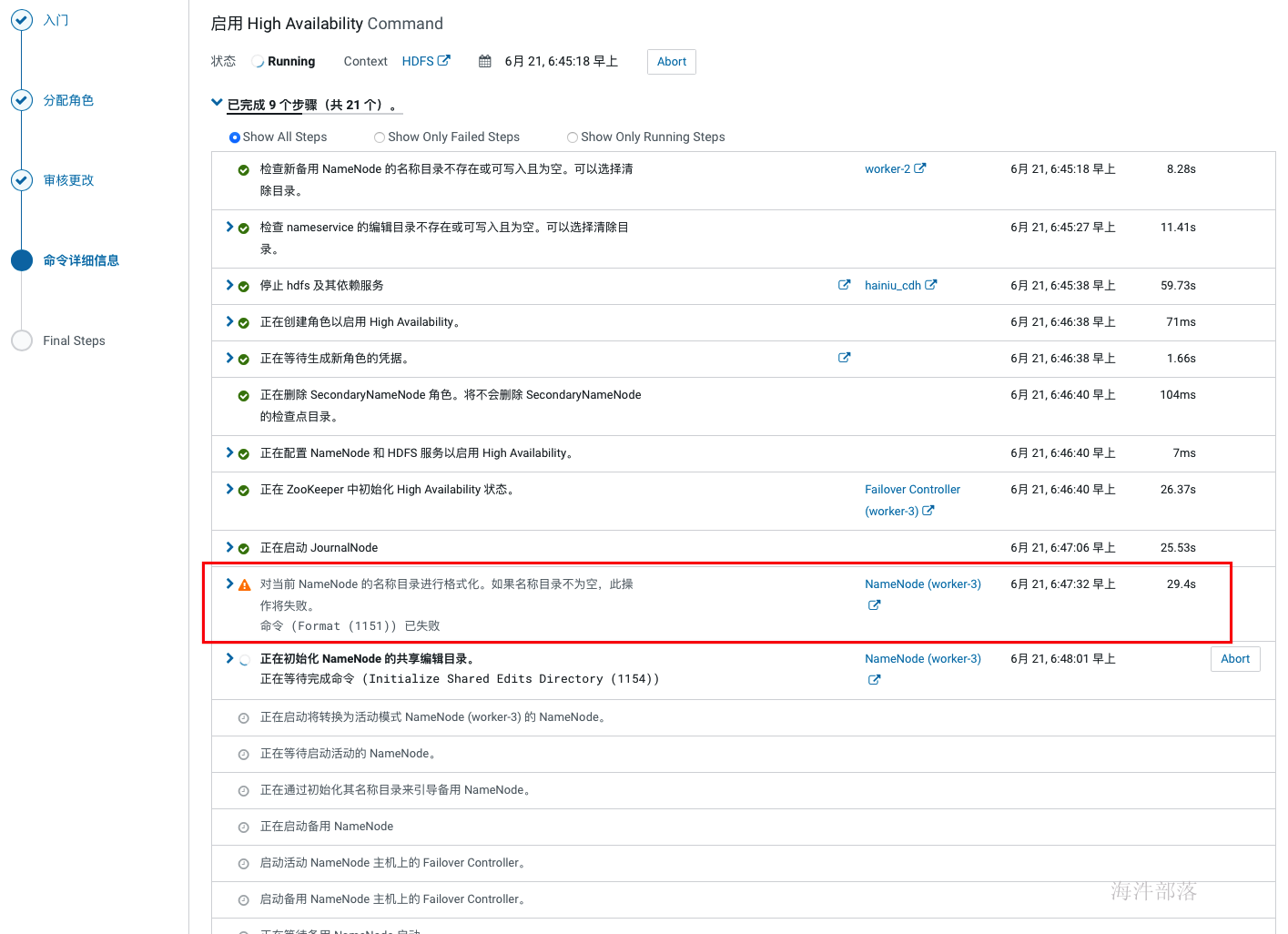
在开启HA的过程中如果hdfs非空,会在格式化的时候报一个警告,因为非空所以格式化失败,不用理会,也不敢理会。
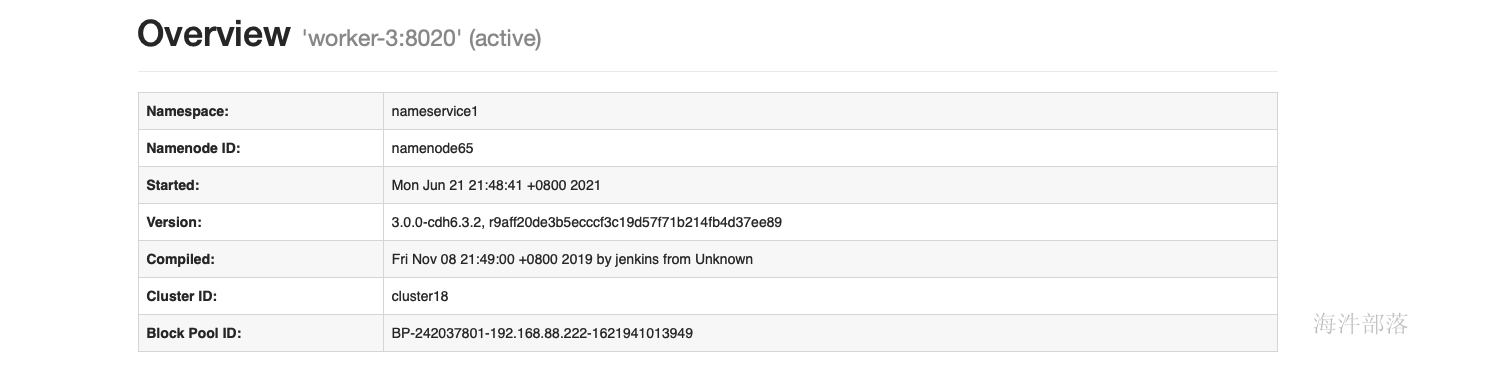
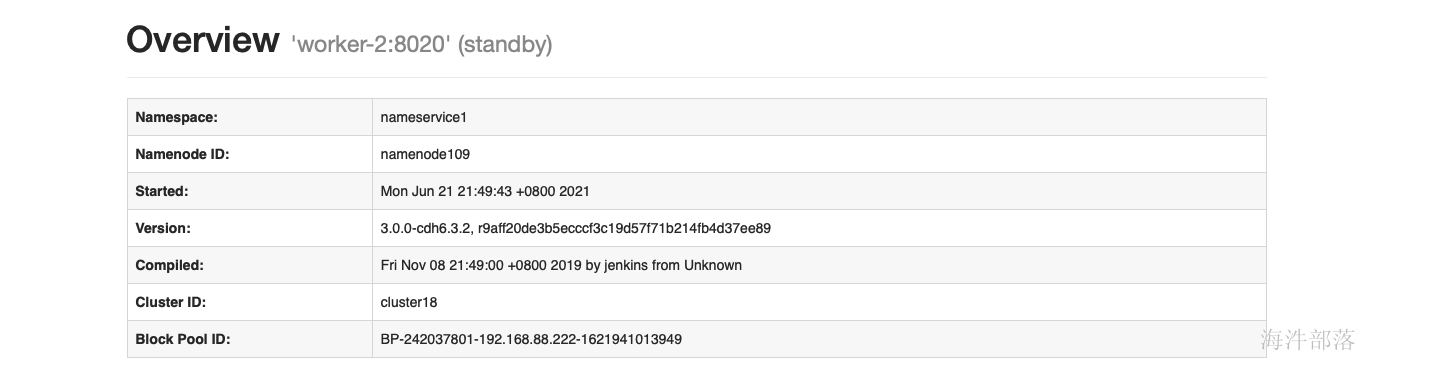
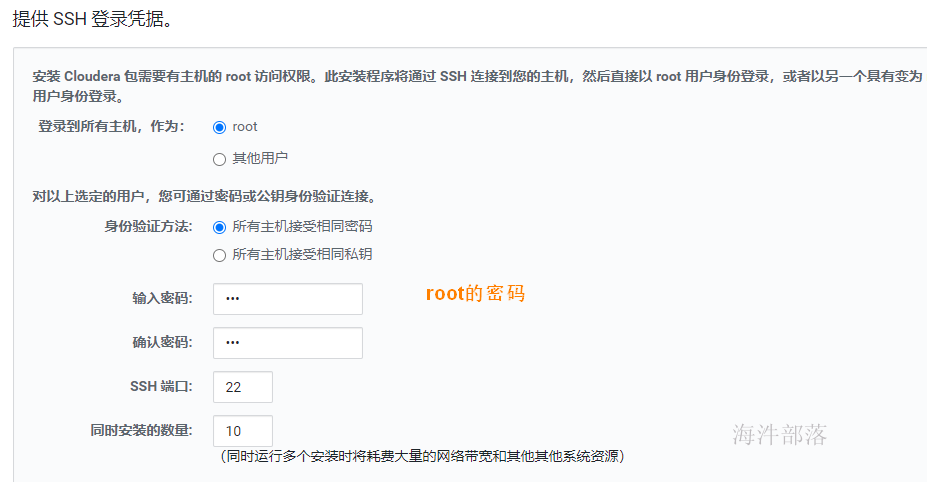
使用命令切换active hdfs haadmin -ns wa -failover worker-3 worker-23 cdh单机安装 需要配置:12G内存、CPU核数8核,磁盘:80G 本次安装不用阿里云yum源 3.1 修改主机名和安装常用工具 # 修改主机名 hostnamectl set-hostname worker-1 # sz, rz工具 yum install -y lrzsz vim firewalld wget 3.2 上传压缩包 上传cdh6.3.2.tar安装包到linux服务器,并解压 tar -xvf cdh6.3.2.tar -C /tmp
expect安装 配置目的:安装 expect 命令,实现脚本交互 expect是一个自动化交互套件,主要应用于执行命令和程序时,系统以交互形式要求输入指定字符串,实现交互通信。 yum install expect -ypstree安装 配置目的:rhel 7 默认没有pstree命令,使用以下命令进行安装,cdh基础依赖。 pstree命令是用于查看进程树之间的关系,即哪个进程是父进程,哪个是子进程,可以清楚的看出来是谁创建了谁 yum install psmisc -yperl 安装 配置目的:解决最小安装时,客户端部署报错,在最小化安装的时候是没有安装perl的。 perl命令是perl语言解释器,负责解释执行perl语言程序 yum install perl -yhttpd服务安装 配置目的:本地源配置使用 yum install httpd mod_ssl -ykudu 需要以下组件 配置目的:kudu依赖 yum install gcc python-devel -y yum install cyrus-sasl* -y 3.3 调整host文件 配置目的:域名访问 # 替换为自己环境实际ip与hostname cat >> /etc/hosts > /etc/sysctl.conf /etc/rc.d/rc.local /sys/kernel/mm/transparent_hugepage/defrag fi EOF # 使用设置马上生效 echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag # 检查设置是否生效 cat /sys/kernel/mm/transparent_hugepage/enabled cat /sys/kernel/mm/transparent_hugepage/defrag # 赋予执行权限 chmod 755 /etc/rc.d/rc.local
配置目的:sudo相关 将当前用户切换到超级用户下,或切换到指定的用户下。 然后以超级用户或其指定切换到的用户身份执行命令,执行完成后,直接退回到当前用户。 具体工作过程如下: 当用户执行sudo时,系统会主动寻找/etc/sudoers文件,判断该用户是否有执行sudo的权限 –>确认用户具有可执行sudo的权限后,让用户输入用户自己的密码确认。 –>若密码输入成功,则开始执行sudo后续的命令。 # 取消别名 unalias cp # 备份sudoers 文件 cp -n /etc/sudoers /etc/sudoers.bak && \ chmod 740 /etc/sudoers && \ sed -i 's/Defaults requiretty/#Defaults requiretty/g' /etc/sudoers && \ chmod 440 /etc/sudoers grep requiretty /etc/sudoers 3.9 配置ntp时间同步【重要】配置目的:在安全认证的时候需要保证每个节点的时间同步,如果不同步则offerset过大,进而影响安全认证,比如凭证生命周期过期,在后面kerberos的原理部门会讲到sessionkey,这个就是一个较短声明周期的key,如果节点间时间差距较大,则直接导致key失败。 # 安装ntp服务 yum install ntp -y # 设置本地地址,注意只能使用ip,ip不变 mv -n /etc/ntp.conf /etc/ntp.conf.bak cat > /etc/ntp.conf > /etc/profile ...这里的主机名称为你要配置的所有节点的hostname,需要在你本机的hosts中也配置了这些节点。
安装时库选择,这里使用的就是我们前面配置的httpd服务,使用本地下载,避免在线安装的各种问题。域名改成自己相应的域名。 parcel的远程安装库为:http://worker-1/cdh6.3.2/ agent的远程安装库为:http://worker-1/cm6.3.1/
选择后,页面展示
JDK安装选项不勾选
如上,当正确填写完parcel地址后,会自动识别出cdh版本,否则……,重新检查在配置httpd服务的时候是否已经执行createrepo.
当agent安装完成后,会进入到安装parcels的界面,这里也是自动进行的,如果中间出现各种错误,可以查看日志定位,在web界面上就可以看到错误日志,也可以在cm的日志中查找,/var/log目录下Cloudera manager server的日志。常见的问题没有正确配置本地源会导致下载失败、分配失败可以优先检查互信配置与hosts配置,过了下载和分配后如果解压失败则优先检查磁盘空间,激活没遇到过失败的。
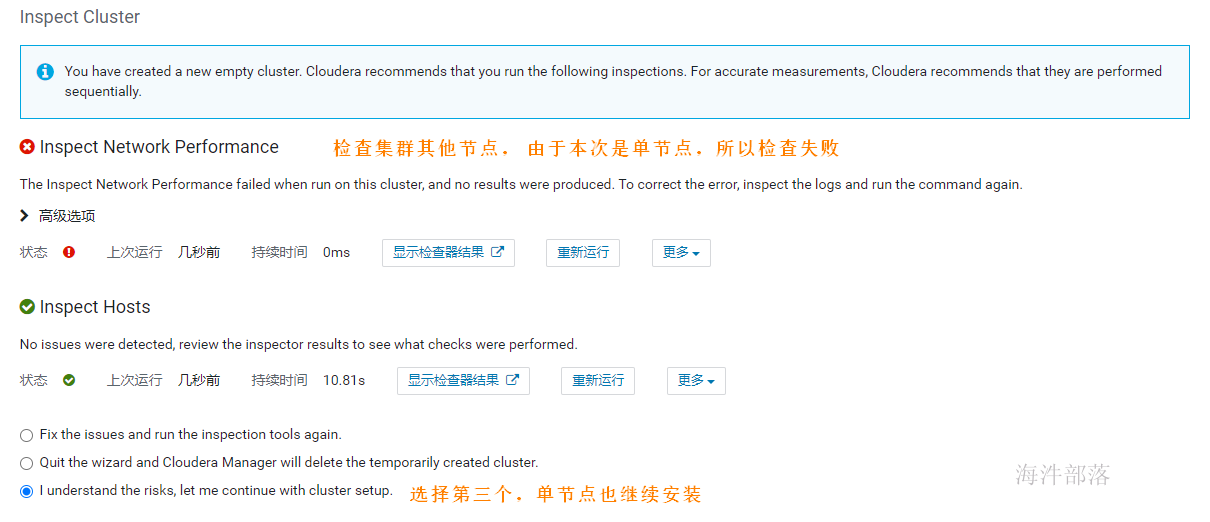
如上激活完成后,跳转到检查环境的页面,点击如下标红位置分别检查网络与hosts,检查通过后才可以继续,单节点安装,在hosts检查的时候会报错,此时选择i understand the risks,let me continue with cluster setup选项 然后点击继续。
如上,环境检查完成后,进行选择安装组件的环节,可以先选择一些基础组件安装,后面需要什么组件再添加即可。比如可以先安装hdfs、hive、hue、yarn、zookeeper,其他服务等集群全部安装完成后再集成,因为部分组件间有依赖关系,如果缺少了依赖,那会导致安装失败。
如上选择好安装组件后点击继续,为每个服务配置节点,如果是单节点就没得选择了,在生产环境中这个规划通常在角色规划中已经规划好,按照架构设计配置即可,通常我们会选择一个管理节点,这个管理节点上部署一些管理服务,其他计算与存储节点上不部署管理服务,如果节点资源紧张也可以在管理节点上部署存储与计算服务,还有一种极端的情况就是节点资源都很紧张,那面就要把服务尽量均衡到每个节点上,除个别服务,比如hive的元库肯定部署在和mysql相同的节点上。
如上完成节点配置后点击继续,进入到元库配置环节,这里配置的信息即我们在12. 创建cm元数据库时创建的那些库的信息,配置完成后点击test connection,只有测试通过后才可以继续。
如上配置完元库信息并通过连接测试后,点击继续,进入服务详细配置界面,如果选择了安装kudu服务,则需要填写四个kudu的目录,如下, Kudu在安装时需要填写以下几项内容: Kudu Master WAL Directory: /kudu_master/fs_wal_dir Kudu Master Data Directories: /kudu_master/fs_data_dirs Kudu Tablet Server WAL Directory: /kudu_tablet/fs_wal_dir Kudu Tablet Server Data Directories: /kudu_tablet/fs_data_dirs 这四个目录,通常与hdfs的盘分离(官方也没有给出为什么,但是在生产中确实遇到过kudu与hdfs同盘导致服务不能启动的问题),我们在测试学习环境下可以设置在一起,如果要使用虚拟机分盘则需要再添加一块虚拟盘,挂载在指定目录下,专门给kudu使用。 生产环境下肯定是配置非常多的数据盘,在配置dfs目录的时候可以点击后面的+增加盘路径(如果所有盘都挂载到了一个目录下,那就不用增加了)
如上配置完成后点击继续,开始服务的安装,如下:
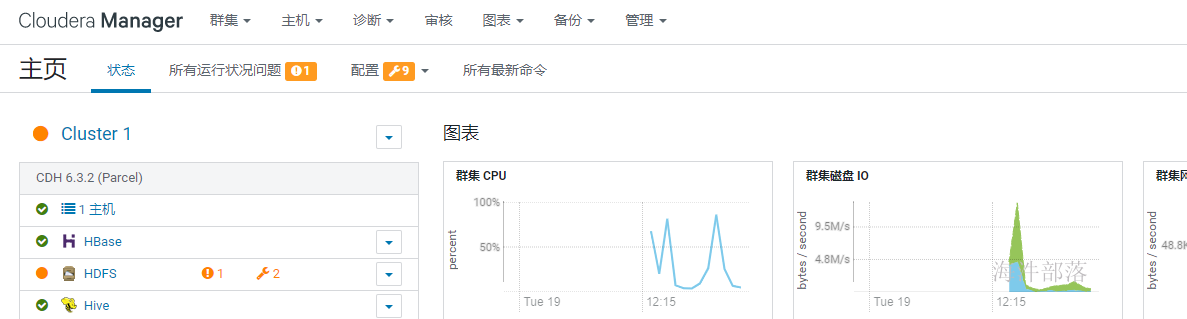
如上,服务全部安装完成后,会进入到cm界面,如下,此时集群安装就完成了。
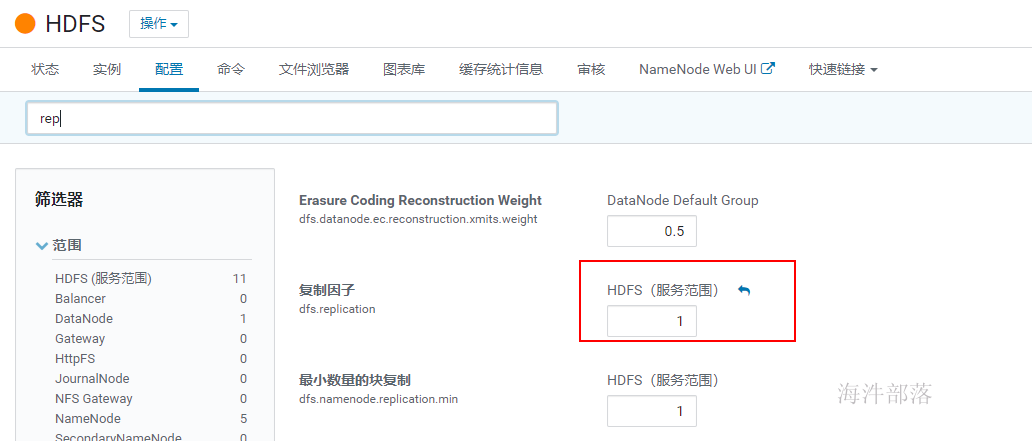
单点部署时HDFS 副本不足告警:Under-Replicated Blocks,这个警告的意思是在一个节点上部署分布式毫无意义,他们希望至少要有三个节点。 针对这种情况,我们就修改 dfs.replication 参数为1(在hdfs组件的配置中搜索replication),并重启配置使其生效。
然后将已经有三个副本的文件递归修改副本数,执行以下命令将所有文件副本数设置为1: sudo -u hdfs hadoop fs -setrep -R 1 /错误状态解除
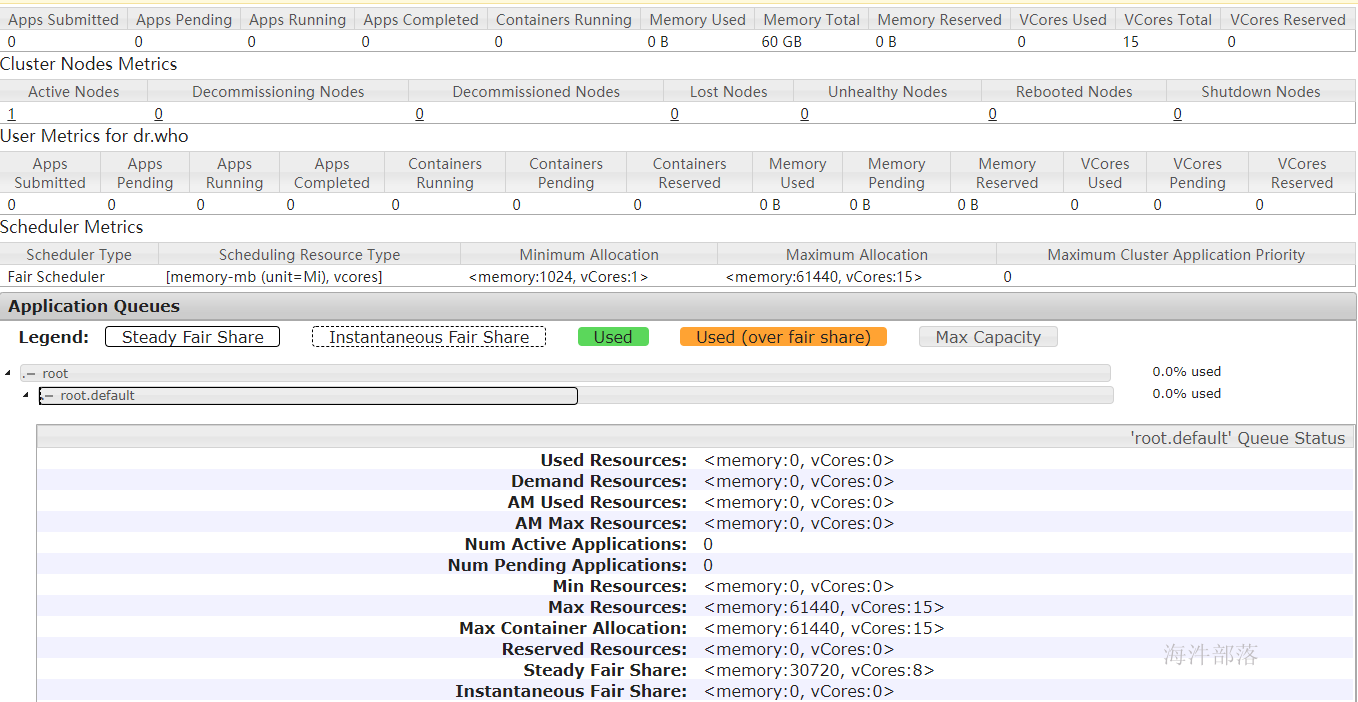
配置前可以看yarn webui,发现资源分配不合理,需要手动配置。 1)配置内存
修改以下配置: # mapper任务内存 mapreduce.map.memory.mb: 1G # reducer任务内存 mapreduce.reduce.memory.mb: 1G # yarn容器内存 yarn.nodemanager.resource.memory-mb : 60G2)配置CPU核
修改以下配置: # mapper任务虚拟CPU核数 mapreduce.map.cpu.vcores: 1 # reducer任务虚拟CPU核数 mapreduce.reduce.cpu.vcores: 1 # yarn容器虚拟CPU核数 # 【注意】:在生产环境里,1个cup核 对应 4G的内存。 yarn.nodemanager.resource.cpu-vcores : 15 # yarn容器最大虚拟CPU核数 yarn.scheduler.maximum-allocation-vcores 154)修改调度器内存数
修改以下配置: # yarn容器最大内存 yarn.scheduler.maximum-allocation-mb 60G配置好后重新更新配置。 查看yarn-webui资源情况
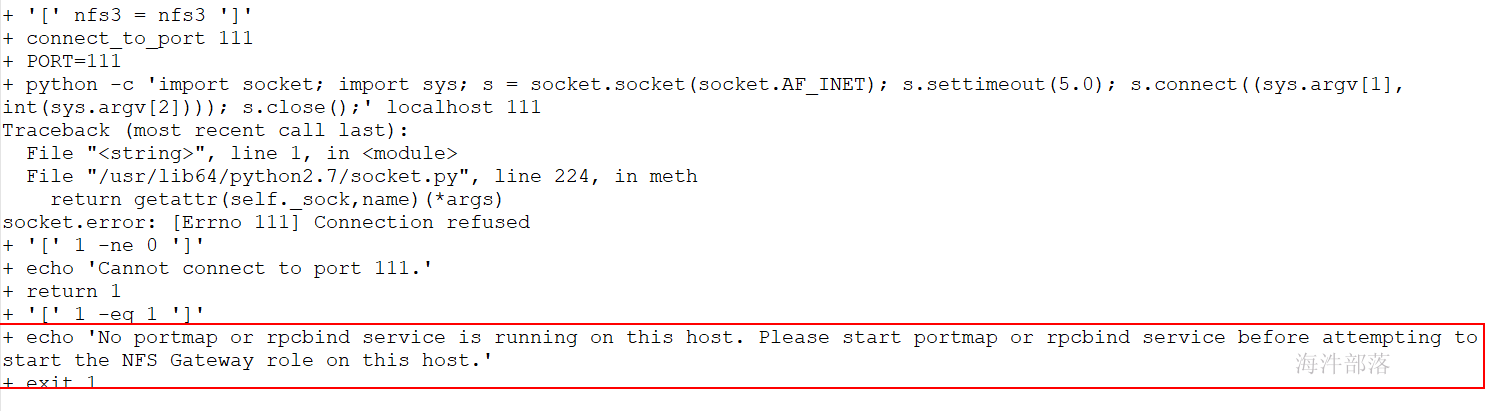
解决方法: # 要启动rpcbind # 安装: yum install nfs-utils rpcbind # 查看状态: systemctl status rpcbind.service # 启动: systemctl start rpcbind.service 3.18.2 安装Cloudera Manager报错有时候安装cloudera会报socket.gaierror: [Errno -2] Name or service not known,或者服务器可能IP或mac地址冲突会引发次错误。导致机器服务不能正常运行和重装。 解决方法: 删除/usr/bin/host文件即可解决问题 3.18.3 启动 JobHistoryServer 报错有时候启动yarn时 jobhistory 历史服务起不来,看日志详细信息后,发现mapred没有/user 的写入权限
解决方法: sudo -u hdfs hadoop fs -chmod 777 /user |






【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |